
Back in the day
In 2003, I was a server administrator working on some of the largest distributed server estates across the world. The concept of applying “patches” for security purposes was at this time in its infancy. Generally, software hotfixes were applied as a response to bugs and failings in applications, than as any kind of security-oriented process.
Of course, we’d had widespread viruses before – mass mailers generally, like Melissa or I Love You. But Microsoft, realizing that Windows in its default format was particularly insecure, were slowly beginning to adapt their model to coping with the possibility of a large-scale network “worm” attack – a virus that spread without interaction on the part of the user across global networks.
At this time Microsoft had begun to issue “alerts” as vulnerabilities in their software were discovered, along with mitigations, workarounds and the patch to fix. The vulnerability in question was “alerted” on July 16 2003, and the hotfix issued at the same time. However, automated tools for deploying hotfixes were few and far between at the time – Microsoft had SUS, which updated clients only, and SMS, the early ancestor of SCCM – and the “Windows Update” tool was not yet part of the operating system. In fact, short of running the tool manually or via a script, the only real option for applying patches was to tell the user to visit www.windowsupdate.com.
Additionally, enterprises had an aversion to change. Change controls at the time were concerned primarily with minimizing business impact, and security wasn’t a major concern of any kind. We highlighted the vulnerability disclosure to our client as part of our weekly infrastructure meeting – this being the days before dedicated security teams existed – but they continually pushed back on the widespread deployment of an operating system patch. Some rather infamous quotes were thrown out in the meeting that stuck with me – “we’re not entirely sure that this could be used in the way Microsoft are indicating”, “let’s see if anyone else gets hacked first” and my personal favourite “we have antivirus – what’s the problem?”
On August 11 2003, while we had another meeting in which we tried to impress the need to deploy the patch, but were told that they were still pulling together a testing process, the infamous Blaster worm made its appearance, and promptly shot straight up the proverbial backside of our client’s biggest inbound sales call center. From there, it spread across the server estate as well, causing endless restarts and huge floods of network traffic as it tried to launch various denial-of-service attacks against Microsoft websites. Our network team panicked somewhat and shut down huge numbers of ports, rendering our response to the attack somewhat limited as SMB and ICMP traffic was all being blocked. The whole organization went into crisis mode, and we were eventually tasked to work through the night applying the patch to the server estate while field services did the same for the endpoint devices.
Without automated tools, we were reduced to using a quick-and-dirty patch script that I produced in order to apply the patch without visiting every server. However, the huge floods of network traffic produced by the worm as it propagated made this very difficult, with the feeling of “treading water” pervading every remote session we initiated. As tiredness set in when we moved to the second day, we found ourselves patching duplicate systems because there was no centralized way to identify a secured endpoint. Eventually, we pushed the patch out to the estate, cleaned the Blaster worm from all of our managed devices, and we were done. It took nearly 48 hours of effort from a six-man team just to secure the servers, and the damage in terms of lost revenue was going to be quite extreme.
The Blaster worm was followed by other famous, fast-propagating worms like Sasser, MyDoom, NetSky and Bagle, and although it had been preceded by notorious events like CodeRed and SQL Slammer, it was the first one that really woke up many of the world’s IT departments to the need for better patching processes and better security software to perform endpoint remediation and threat detection. Not long after, Microsoft released Windows Server Update Services, a fully-integrated Windows patching tool that allowed tight control over the release and installation of hotfixes, patches and service packs. Security software came on in leaps and bounds, with application management and intrusion detection being added to the defense strategies of enterprise environments. Patch management became a monthly cycle of assessment, testing, deployment and reporting that ensured compliance was in place to avoid any future network worms.
The modern world
And, like everything does, slowly we began to let out diligence slip.
“Worms” fell out of fashion, having been the staple of young hackers looking to make a name for themselves by spreading as fast as possible and causing great disruption. Viruses moved on to new forms – keyloggers to steal banking credentials, ransomware to encrypt files and demand payment, bot armies to launch huge distributed-denial-of-service attacks for extortion purposes. Organized crime got in on the game and made it a business, rather than an anarchic pastime. Highly targeted hacks – spear phishing – were the route into networks to steal data and intellectual property. It seemed that the day of the self-propagating network worm was officially over.
Alongside this change, our reliance on applications and Internet services has grown ever greater. Changes to our environments are ever more tightly controlled because operational impact has grown so much greater than it was previously. Moving away from legacy software has become a huge challenge because enterprises are terrified of having an adverse effect on existing revenue streams or processes. Toothless regulations have ensured that often the cost of preventing data breaches is higher than that of paying fines and dealing with bad publicity in the event it does happen. More and more of our devices are internet-connected, yet not designed with security in mind.
And amidst all of this we’ve become somewhat inured to the daily output of security vulnerabilities and vendor disclosure. I’m sure not many batted an eyelid when it was announced that Shadow Brokers had compromised a set of vulnerabilities allegedly used in a nation-state hacking toolkit by America’s National Security Agency. Microsoft responded by announcing they’d already made patches available for the vulnerabilities. Even though some of the vulnerabilities were critical and affected huge amounts of Windows endpoints, they were merely passed into the neverending security cycle for processing – because no-one would ever throw out a network worm any more anyway, after all, that’s so 2003?
Well, the events of 12 May 2017 indicate that we’re guilty of massive complacency. Hackers weaponized a vulnerability to spread ransomware, and added network worm capability to ensure self-propagation. Within a few hours, 75,000 systems in 57 countries had been infected with ransomware that encrypted all accessible data and demanded a payment to release the files. With hindsight, it seems incredibly naïve to think that no-one would ever consider putting together the insidious, revenue-generating attack vector of encryption ransomware and combine it with self-propagating worm capability – after all, the more people you hit, the more money you stand to make.
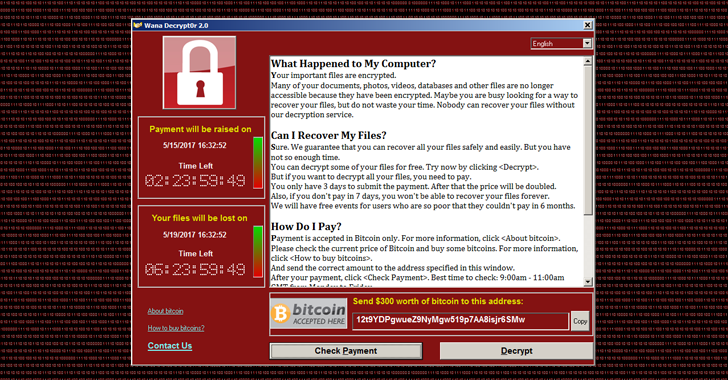
What makes this worse is that it appears to have affected UK NHS systems quite badly. Disrupting day-to-day workloads is bad enough, but in healthcare, lives are at stake. A huge amount of non-emergency appointments have been cancelled, making this probably the first worm attack that has done significant damage to a country’s actual social infrastructure.
Notwithstanding the fact that this vulnerability – MS17-010 – was a result of a nation state hoarding vulnerabilities for their own cyber warfare and spying purposes, rather than practicing responsible disclosure, the initial alert was issued on March 14 2017. That means we’ve had 59 days to deal with the vulnerability from disclosure to weaponization. Those people referring to it as a “zero-day” attack are completely wrong – almost two months has gone by in which the issue could have been remediated. Now contrast this with the Blaster worm, where there were only 26 days from disclosure to weaponization. In 2003, we had 26 days to respond, at a time when we had little or no automated tools to use, no standard processes for dealing with security, no buy-in from management, and very little experience of such an attack. In 2017, we had 59 days to respond, with a plethora of deployment tools and security software at our disposal, fourteen years of honing security processes, and plenty of anecdotal experience around the issue. So despite having all of the historical data and experience, the tools, the fine-tuned processes, and nearly three times longer to deal with the problem, what was the end result?
Exactly the same. Groundhog Day. We got owned by a network worm – again.
What did we do wrong?
Of course, we can put this in context. I’m sure many enterprises weren’t affected by this because they had a defense-in-depth strategy that provided mitigation. Defense-in-depth is key. The old anecdote tells of the man who leaves his expensive watch in his trouser pocket, and it gets broken when it goes through the washing machine. Who should have checked – the man himself, or his wife when loading the washing machine? In security, there is only one answer that protects your assets – they both should have checked, each providing mitigation in case the other layer fails.
So I suppose that the WannaCry worm – for that is the name that it has been given – has been somewhat reduced in its scope because many of the enterprises in the world have learned from the past fourteen years. But it’s clear that not everyone is on board with this. The NHS, in particular, have suffered badly because they are still wedded to older systems like Windows XP, despite the operating system being out of support for several years now. And this is because of legacy applications – ones that don’t port easily to the latest versions of Windows, forcing them to be persisted on older, vulnerable systems.
But of course there is also a failure to effectively patch other, supported systems that is contributory to this. After Blaster and Sasser patches were deployed quickly and without fuss, because the pain of the attack was still raw in the memory. Emphasis was placed more on backout plans in the event that application issues were caused, rather than insisting on rigorous testing prior to deployment. As network worm attacks decreased, time given to testing has exponentially increased. Many organizations now have a three-month window for patching client systems, which although it has served them well in the intervening time, is not good enough if we can see weaponization of a vulnerability inside of this window. In many cases, the window for patching of servers can be exponentially longer.
Administrative rights are still an issue as well. Whilst this particular vulnerability didn’t need administrative rights, the scope of potential damage to a system is always increased by the end-users having administrative rights, no matter what the reason. I still see many environments where end-users have simply been given administrative rights without any investigation into why they need them, or any possible mitigation.
Now I’m not going to sit here and cynically suggest that merely buying some software can save you from these sorts of attacks, because that would be a) a bit insensitive given that healthcare outlets are suffering the brunt of this outbreak, and b) because it simply isn’t true. Of course, adopting the right tools and solutions is a fundamental part of any defense-in-depth solution, but it isn’t anywhere near the whole thing.

What can we do better?
Traditional antivirus isn’t great at catching exploits like this, so there is a rethink needed about how you approach security technologies. Bromium vSentry is an example of the “new wave” of security tech that we’ve had great success with, along with things like Cylance. But that’s not enough on its own; although solutions like these offer you a good starting point, it’s important to adopt a holistic approach.
Getting away from legacy systems and legacy apps is paramount. There’s no point having a comprehensive patching system in place if patches aren’t being issued for your core operating environment any more! There are many application remediation technologies that can help with moving incompatible legacy apps to supported – and more secure – operating systems like Windows 10. Once they’re remediated, they are portable, modular, even cloud-based, and can easily cope with the rolling cadence of Windows feature updates. Cloudhouse, Numecent, Turbo.net, etc. – we’ve had great success with these across many different verticals.
Ensuring you have a comprehensive patching process is also vital. It’s not just the OS itself – tech like Java, Flash, Office and the browser are examples of key areas that are often exploited. This has to encompass testing, deployment, mop-up and reporting in order to be fully effective, and if your users are mobile and/or use their own devices, you may need something beyond the traditional tools to accomplish this.
Application management – preventing untrusted code from running – is another key approach. You can use whitelisting technologies like AppLocker or Ivanti DesktopNow to create trusted lists of executable code, and combine this with new security features in Windows 10 like Device Guard and Credential Guard to produce a highly secure, but adaptable, solution. Many malware attacks such as WannaCry would be effectively mitigated by using an approach like this as part of an overall security strategy.
But security and usability don’t have to be polar opposites. Being secure doesn’t mean sacrificing user experience. There are some trade-offs to be made, but precise monitoring combined with robust processes and documentation can ensure that providing the right level of security doesn’t have to come at the cost of compromising user productivity. Striking that balance cuts to the very heart of an effective security policy.
And naturally, there are many other areas a security strategy needs to concentrate on for a true defense-in-depth approach. The risk that one control fails or is bypassed needs to be mitigated by others. Locking down USB devices, removing administrative rights, detecting threat-based behaviour, managing firewalls, web filtering, removing ads – the list of things to cover is very broad in scope. What’s more, all of this needs to merge into an effective business process that not only covers all of the things mentioned above but deals with incident response and learning. When the GDPR regulations come along in 2018, the penalties for security breaches will increase to a level where there is a real financial risk associated with failure. It’s a favourite saying in the security community that breaches are a case of “not if, but when”, and recent events should remind us that this has never rung truer.
Summary
All in all, we should have learned from the mistakes of the past, but the WannaCry worm has shown us that in many areas, we are still failing. Security needs to be done by default, not just when we get exposed. With more and more devices coming online and integrating themselves into our enterprise infrastructure, the potential for malware like this to not only cost us money, but to disrupt our entire society and even threaten people’s lives, should act as a well-overdue wake-up call. Security is an ongoing process, and it’s not something we’re ever going to fix – it’s a mindset that needs to run through IT operations from top to bottom. But if you take a diligent approach, choose the right technologies, implement your processes correctly and make sure you have good people on your team – then there’s no reason you shouldn’t be able to stop your enterprise becoming a victim of the next high-profile attack.
Update – there is a very interesting write-up on how one security researcher’s instinctive response to seeing the behaviour of the malware effectively stopped WannaCry in its tracks due to a poorly-executed analysis-evasion technique. Details here

